 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Space as a Scratchpad for Editable Text-to-Image Generation
Jan 21, 2026Recent progress in large language models (LLMs) has shown that reasoning improves when intermediate thoughts are externalized into explicit workspaces, such as chain-of-thought traces or tool-augmented reasoning. Yet, visual language models (VLMs) lack an analogous mechanism for spatial reasoning, limiting their ability to generate images that accurately reflect geometric relations, object identities, and compositional intent. We introduce the concept of a spatial scratchpad -- a 3D reasoning substrate that bridges linguistic intent and image synthesis. Given a text prompt, our framework parses subjects and background elements, instantiates them as editable 3D meshes, and employs agentic scene planning for placement, orientation, and viewpoint selection. The resulting 3D arrangement is rendered back into the image domain with identity-preserving cues, enabling the VLM to generate spatially consistent and visually coherent outputs. Unlike prior 2D layout-based methods, our approach supports intuitive 3D edits that propagate reliably into final images. Empirically, it achieves a 32% improvement in text alignment on GenAI-Bench, demonstrating the benefit of explicit 3D reasoning for precise, controllable image generation. Our results highlight a new paradigm for vision-language models that deliberate not only in language, but also in space. Code and visualizations at https://oindrilasaha.github.io/3DScratchpad/
Understanding and Exploiting Object Interaction Landscapes
Nov 08, 2016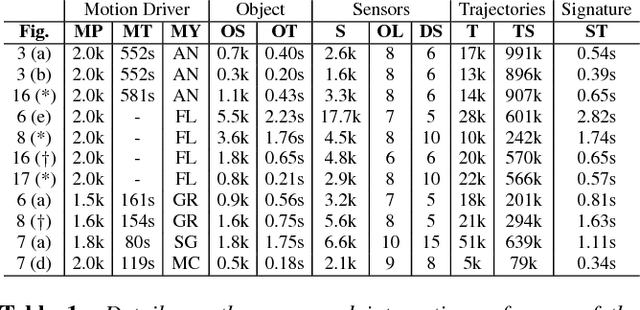
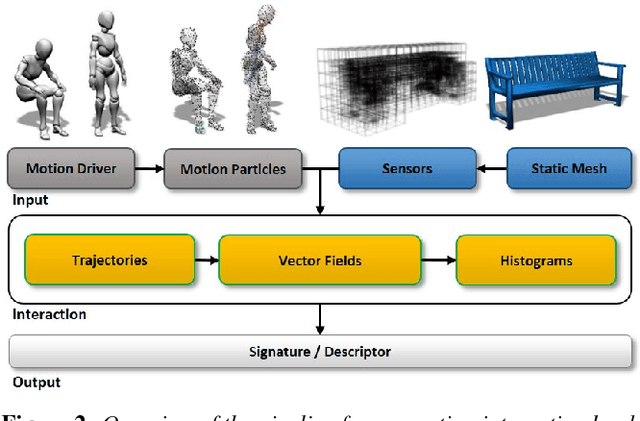


Interactions play a key role in understanding objects and scenes, for both virtual and real world agents. We introduce a new general representation for proximal interactions among physical objects that is agnostic to the type of objects or interaction involved. The representation is based on tracking particles on one of the participating objects and then observing them with sensors appropriately placed in the interaction volume or on the interaction surfaces. We show how to factorize these interaction descriptors and project them into a particular participating object so as to obtain a new functional descriptor for that object, its interaction landscape, capturing its observed use in a spatio-temporal framework. Interaction landscapes are independent of the particular interaction and capture subtle dynamic effects in how objects move and behave when in functional use. Our method relates objects based on their function, establishes correspondences between shapes based on functional key points and regions, and retrieves peer and partner objects with respect to an interaction.